更新时间:2022-12-07 来源:黑马程序员 浏览量:
将一幅图片输入到yolo模型中,对应的输出是一个7x7x30张量,构建标签label时对于原图像中的每一个网格grid都需要构建一个30维的向量。对照下图我们来构建目标向量:

20个对象分类的概率
对于输入图像中的每个对象,先找到其中心点。比如上图中自行车,其中心点在黄色圆点位置,中心点落在黄色网格内,所以这个黄色网格对应的30维向量中,自行车的概率是1,其它对象的概率是0。所有其它48个网格的30维向量中,该自行车的概率都是0。这就是所谓的"中心点所在的网格对预测该对象负责"。狗和汽车的分类概率也是同样的方法填写
2个bounding box的位置
训练样本的bbox位置应该填写对象真实的位置bbox,但一个对象对应了2个bounding box,该填哪一个呢?需要根据网络输出的bbox与对象实际bbox的IOU来选择,所以要在训练过程中动态决定到底填哪一个bbox。
2个bounding box的置信度
预测置信度的公式为:
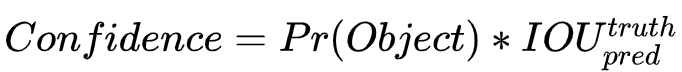
利用网络输出的2个bounding box与对象真实bounding box计算出来。然后看这2个bounding box的IOU,哪个比较大,就由哪个bounding box来负责预测该对象是否存在,即该bounding box的Pr(Object)=1,同时对象真实bounding box的位置也就填入该bounding box。另一个不负责预测的bounding box的Pr(Object)=0。
上图中自行车所在的grid对应的结果如下图所示:

损失就是网络实际输出值与样本标签值之间的偏差:

yolo给出的损失函数:
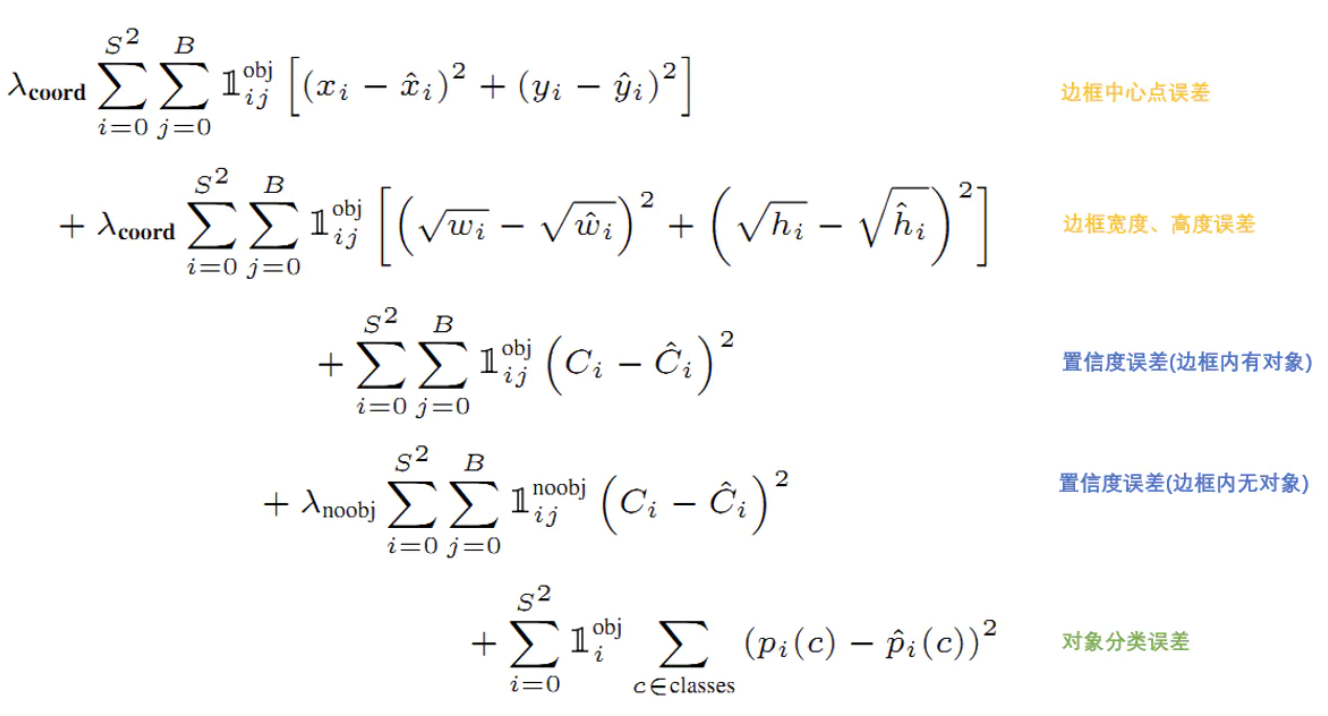
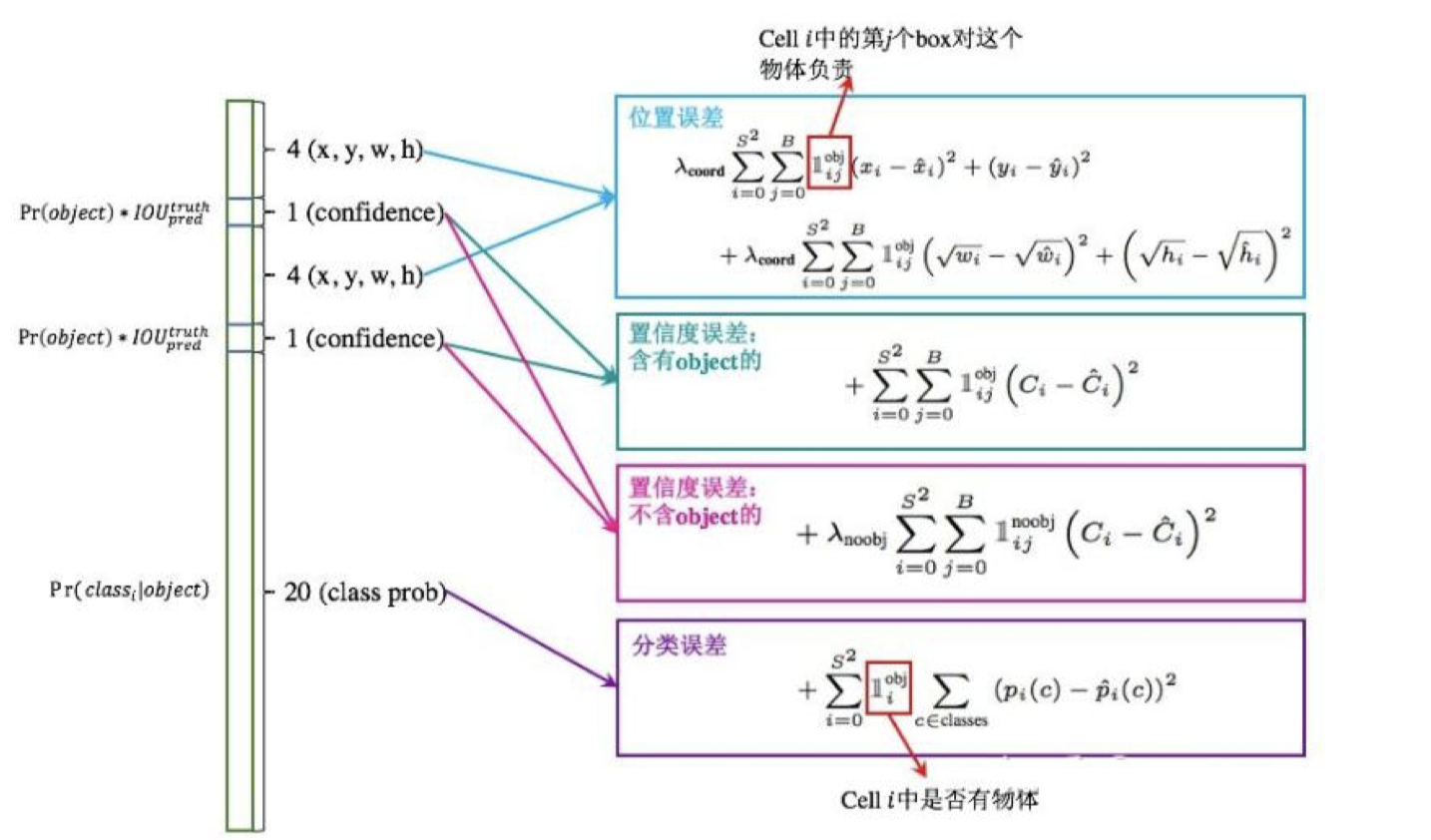
Yolo先使用ImageNet数据集对前20层卷积网络进行预训练,然后使用完整的网络,在PASCAL VOC数据集上进行对象识别和定位的训练。
Yolo的最后一层采用线性激活函数,其它层都是Leaky ReLU。训练中采用了drop out和数据增强(data augmentation)来防止过拟合。
将图片resize成448x448的大小,送入到yolo网络中,输出一个 7x7x30 的张量(tensor)来表示图片中所有网格包含的对象(概率)以及该对象可能的2个位置(bounding box)和可信程度(置信度)。在采用NMS(Non-maximal suppression,非极大值抑制)算法选出最有可能是目标的结果。
总结:yolo模型预测速度非常快,处理速度可以达到45fps,其快速版本(网络较小)甚至可以达到155fps。训练和预测可以端到端的进行,非常简便。准确率会打折扣对于小目标和靠的很近的目标检测效果并不好。

















 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营

















.jpg)